Q-learning의 핵심은 정책(Policy) 없이도 환경을 탐색하며 최적의 행동을 학습할 수 있는 모델-프리 강화 학습(Model-Free Reinforcement Learning) 알고리즘 이다.
아래와 같은 테이블이 있다고 치자

4x4 테이블에서 한 칸을 4개의 칸으로 나누게 된다.
Q-learning의 시작을 (0,0) 라고 설정 하고 어딘가 있는 목적지 까지 최적의 스텝을 밟아가면서 학습을 진행 한다.

이렇게 모든 테이블에 0을 집어 넣으며 업데이트를 진행 한다
첫 번째 에피소드에서 목적지 근처에 도달하게 되면 해당 방향을 1로 업데이트 한다.
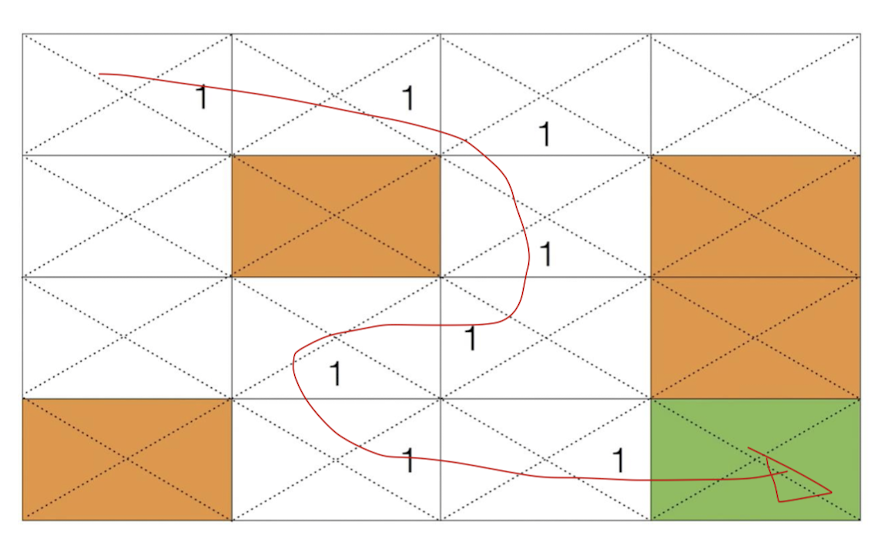

Q의 값을 계속해서 업데이트 하는 형식으로 진행하게 되는데 이런식으로는 최적의 결과가 나오지 않을 것 이다.
그래서
Exploit & Exploration 을 같이 사용하게 된다.
1이라는 값을 점차 줄여나가면서 탐색을 진행하는 방식은 초기에는 탐험(Exploration)에 더 중점을 두고, 점차 이용(Exploitation)으로 전환하는 과정을 의미한다.
이를 효과적으로 수행하기 위해 탐험 감소 기법(Exploration Decay) 을 적용한다.
ϵ의 값을 점차 줄여나가면서 초기에는 높은 ϵ 값을 통해 다양한 행동을 탐색하고, 학습이 진행 됨에 따라서 ϵ의 값을 줄여 더 많은 시간을 최적의 경로를 찾는데 사용 하게 됩니다.

'AI' 카테고리의 다른 글
| BERT 언어 모델 (1) | 2025.02.05 |
|---|---|
| jupyter notebook 커널 죽는 문제 (0) | 2025.01.27 |
| 옵티마이저 Optimizer (0) | 2024.12.01 |
| [GPT] 모델의 구조 (1) | 2024.11.30 |
| [프로젝트] 실시간 얼굴 감정 서비스 (0) | 2024.05.21 |


