BERT 모델은 Transformer 모델에서 Encoder 부분 사용한 언어 모델 입니다.
https://github.com/codertimo/BERT-pytorch
GitHub - codertimo/BERT-pytorch: Google AI 2018 BERT pytorch implementation
Google AI 2018 BERT pytorch implementation. Contribute to codertimo/BERT-pytorch development by creating an account on GitHub.
github.com
코드를 기반으로 BERT 모델의 전반적인 학습 과정에 대해 소개해보겠습니다.
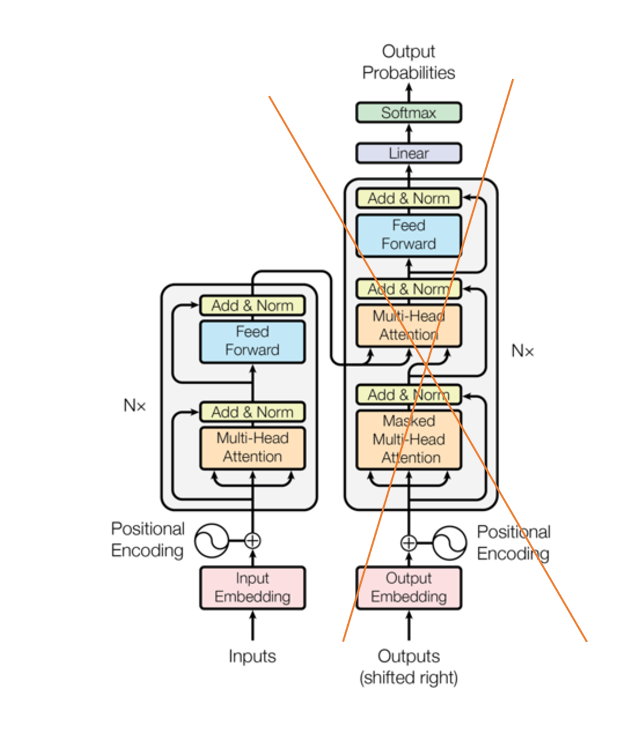
Transformer 모델의 구조를 확인하면 Encoder 부분과 Decoder 부분을 나눌수 있습니다.
오른쪽에 X 표시를 한 곳은 Decoder 부분이고 앞에 부분이 Encoder 부분입니다.
BERT는 GPT 와 다르게 양방향으로 모델입니다.
양방향 모델이란 다음에 올 단어를 예측하는데 있어 그 [Mask] 된 토큰 앞 뒤로 살펴보아 가장 높은 확률의 단어를 출력하는 모델 입니다.
이러한 기능을 할 수 있게 하는 것은 BERT 모델을 PreTrain 할 때 MLM,NSP 테스크를 할 수 있게 학습하는 것 입니다.

MLM, NSP Task를 하기 위해 데이터에 라벨링을 진행합니다.
dataset.py
def random_word(self, sentence):
tokens = sentence.split()
output_label = []
#튜플 형태로 {i,token} 으로 생성
for i, token in enumerate(tokens):
prob = random.random()
if prob < 0.15:
prob /= 0.15
# 80% randomly change token to mask token
if prob < 0.8:
tokens[i] = self.vocab.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
tokens[i] = random.randrange(len(self.vocab))
# 10% randomly change token to current token
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index))
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(0)
return tokens, output_label
def __getitem__(self, item):
t1, t2, is_next_label = self.random_sent(item)
t1_random, t1_label = self.random_word(t1)
t2_random, t2_label = self.random_word(t2)
# [CLS] tag = SOS tag, [SEP] tag = EOS tag
t1 = [self.vocab.sos_index] + t1_random + [self.vocab.eos_index]
t2 = t2_random + [self.vocab.eos_index]
t1_label = [self.vocab.pad_index] + t1_label + [self.vocab.pad_index]
t2_label = t2_label + [self.vocab.pad_index]
segment_label = ([1 for _ in range(len(t1))] + [2 for _ in range(len(t2))])[:self.seq_len]
bert_input = (t1 + t2)[:self.seq_len]
bert_label = (t1_label + t2_label)[:self.seq_len]
padding = [self.vocab.pad_index for _ in range(self.seq_len - len(bert_input))]
bert_input.extend(padding), bert_label.extend(padding), segment_label.extend(padding)
output = {"bert_input": bert_input,
"bert_label": bert_label,
"segment_label": segment_label,
"is_next": is_next_label}
return {key: torch.tensor(value) for key, value in output.items()}
이렇게 라벨링을 진행 합니다.
다음으로는 Input_Text에 대한 임베딩입니다.
임베딩에는 3가지가 존재합니다.
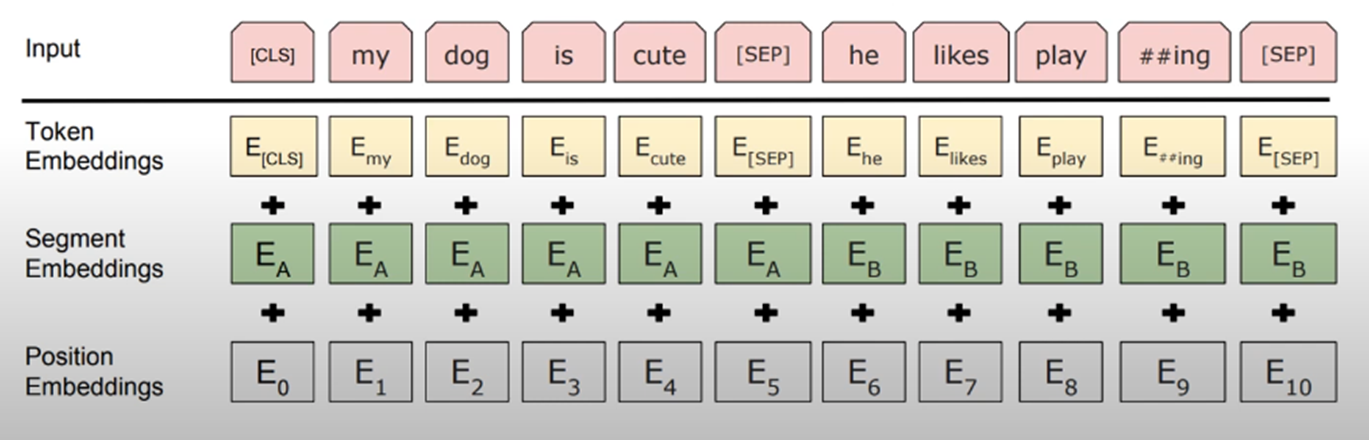
Token Embedding, Segment, Embdeddings
여기서 Segment 임베딩은 BERT Task 인 NSP를 하는데 영향을 줍니다.
이 모든 과정을 동시에 진행합니다.
그 다음 멀티 헤드 어텐션, 정규화 과정을 거쳐 모델을 학습하게 됩니다.
이 과정에서 제일 중요하다고 생각한 것은 MLM,NSP task 였던거 같습니다.
이렇게 학습된 모델에다가 특정 task를 수행하는 layer와 data를 변경하여 다시 학습하는 것이 Fine-Tuning 입니다.
https://www.notion.so/BERT-191b7e7082ee8085bd55f1ac751df986
BERT 마무리 | Notion
Bert 모델은 특수한 언어 모델을 처리할 수 있게 모델을 파인튜닝 하는 것에 적합한 모델이다. 다른 말로는 전이모델이라고도 불린다.
fringe-girdle-ad7.notion.site
자세한 코드에 대해서는 노션 페이지를 만들어 정리하였습니다.
틀리내용이나 잘못된 내용 있으면 말씀해주세요
'AI' 카테고리의 다른 글
| BPE 서브워드 토크나이저 (0) | 2025.05.17 |
|---|---|
| jupyter notebook 커널 죽는 문제 (0) | 2025.01.27 |
| Q-learning (1) | 2024.12.04 |
| 옵티마이저 Optimizer (0) | 2024.12.01 |
| [GPT] 모델의 구조 (1) | 2024.11.30 |


